- Published on
系统设计面试:内幕指南
- Authors

- Name
- AgedCoffee
- @__middle__child
第 01 章:从 0 到百万用户
在以下情况,非关系型数据库可能是正确的选择:
- 你的应用程序需要超低延迟
- 你的数据是非结构化的,或者你没有任何关系型数据。
- 你只需要序列化和反序列化数据(JSON、XML、YAML 等)。
- 你需要存储大量的数据
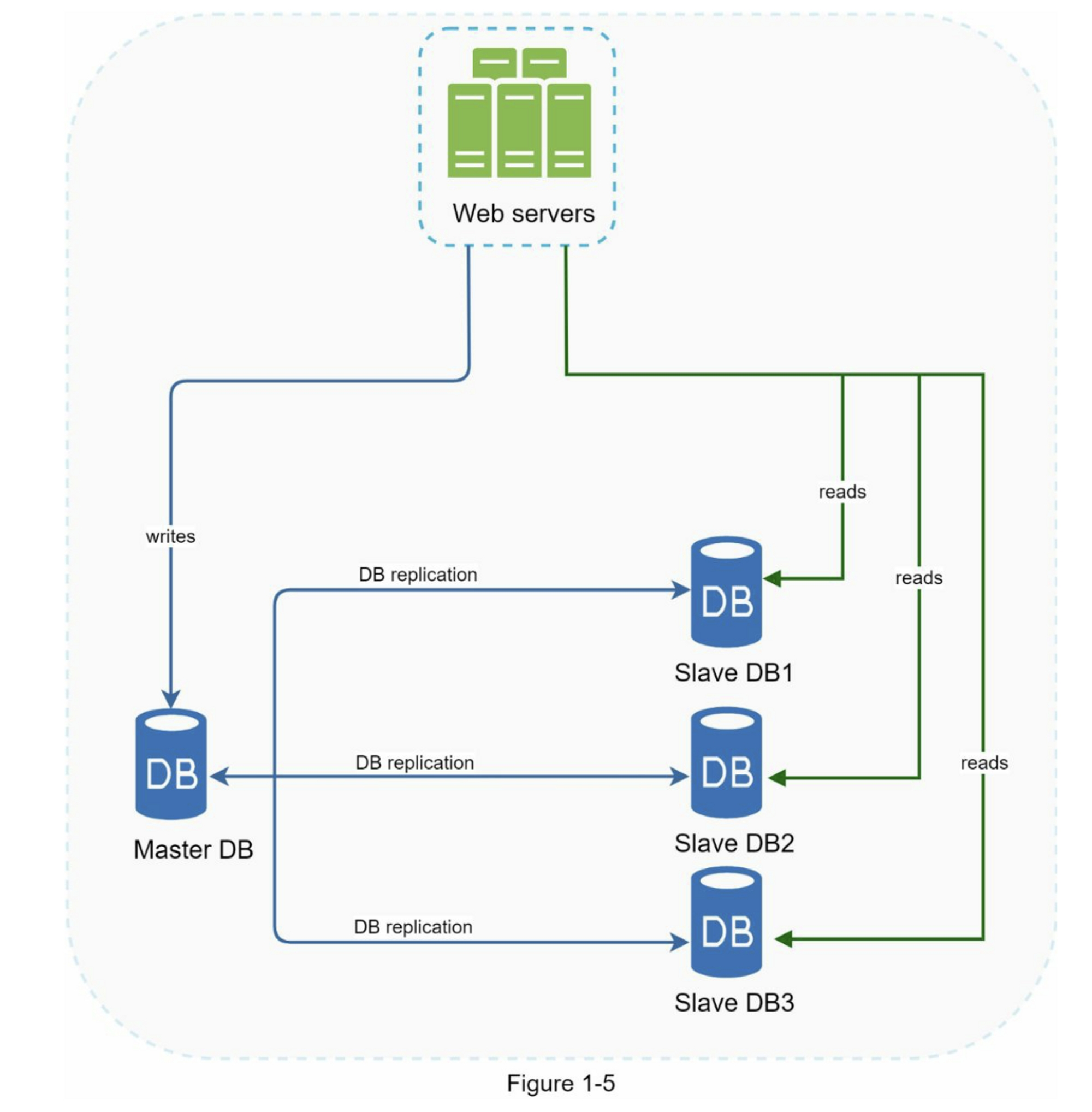
有主从数据库的设计
主数据库通常仅支持写的操作。从数据库从主数据库中复制数据并且仅支持读操作。所有修改数据的命令,如:insert,delete,update 都必须发送到主数据库。
大多数应用程序对读写比的要求较高,因此,系统中从库的数量通常大于主库的数量。
使用缓存的注意事项
决定何时使用缓存:当数据频繁读取但不经常修改时,请考虑使用缓存。由于缓存数据存储在易失的内存中,所以缓存服务器不适合持久化数据。例如,如果缓存服务器重启了,内存中所有的数据都会丢失,因此,重要的数据应该保存在持久数据存储中。
过期策略:实施过期策略是个好习惯,一旦缓存数据过期,它就会从缓存中删除。当没有过期策略时,缓存数据将被永久的保存在内存中。建议不要将过期时间设置的太短,因为这会导致系统过于频繁地从数据库重新加载数据。于此同时,建议不要将过期时间设置的太长,因为数据可能会过时。
一致性:这涉及保持数据存储和缓存同步。一致性可能会发生,因为对数据存储和缓存的修改操作不在一个事务中。在跨多个区域扩展时,保持数据存储和缓存之间的一致性具有挑战性。有关更多信息,请参阅 Facebook 发布的“Scaling Memcache at Facebook”论文[7]。
减少故障:单个缓存服务器代表了潜在的单点故障(SPOF),在维基百科中定义如下:“单点故障(SPOF)是系统的一部分,如果它发生故障,将使整个系统停止工作。”[8]。因此,建议在不同数据中心使用多个缓存服务器,以避免单点故障 (SPOF)。另一种推荐的方法是通过配置比所需的大小还多一定百分比的内存。这在内存使用量上升的时候起到一个缓冲的效果。
百万用户及以上
扩展系统是一个持续迭代的过程。重复我们在本章中学到的知识可以使我们走的更远。为了超越百万用户,需要更多的微调和新的策略。例如,你可能需要优化你的系统,将系统解耦为更小的服务。本章所学的知识为应对新的挑战提供了一个良好的应对基础。在本章最后,我们提供了一个关于我们如何扩展我们系统以支持数百万用户的总结:
- 保持 Web 层无状态
- 在每一层建立冗余
- 尽可能缓存数据
- 支持多个数据中心
- 在 CDN 中托管静态数据
- 通过分片扩展数据层
- 将层拆分为单独的服务
- 监控你的系统并使用自动化工具
第 02 章:粗略估算
假设:
- 每月活跃用户为 3 亿。
- 50% 的用户每天使用 Twitter。
- 用户平均每天发布 2 条推文。
- 10% 的推文包含媒体。
- 数据存储时间为 5 年。
估算:查询每秒次数(QPS)估计:
- 每日活跃用户(DAU)= 3 亿 * 50% = 1.5 亿
- 推文 QPS = 1.5 亿 * 2 推文 / 24 小时 / 3600 秒 = 约 3500
- 峰值 QPS = 2 * QPS = 约 7000
(译者注:这里更准确地说应该估算的 TPS,而不是 QPS。仅个人观点,原文翻译还是保持原作者意思为 QPS。)
我们这里只会估算媒体存储。
- 平均推文大小:
- 推文 ID 64 bytes(字节)
- 文本 140 bytes(字节)
- 媒体 1MB
- 媒体存储:1.5 亿 _ 2 _ 10% * 1MB = 每天 30TB
- 5 年媒体存储:30TB _ 365 _ 5 = 约 55PB
第 03 章:系统设计面试框架
总结了一份 "该做" 和 "不该做" 的清单。
该做
- 要问清楚。不要认为你的假设是正确的。
- 了解问题的要求。
- 既没有正确的答案,也没有最好的答案。为解决年轻创业公司的问题而设计的解决方案与拥有数百万用户的老牌公司的解决方案不同。确保你理解了要求。
- 让面试官知道你在想什么。与你的面试官沟通。
- 如果可能的话,提出多种方法。
- 一旦你与你的面试官就蓝图达成一致,就对每个组件进行详细说明。先设计最关键的部分。
- 向面试官反映想法。一个好的面试官会把你当作一个团队伙伴和你一起合作。
- 永不言弃。
不该做
- 不要对典型的面试问题没有任何准备。
- 在没有弄清需求和假设的情况下,不要贸然提出解决方案。
- 在开始的时候,不要对一个单一的组件进行太多细节的研究。首先给出高层次的设计,然后再深入探讨。
- 如果你被卡住了,不要犹豫,请求提示。
- 再次强调,要进行沟通。不要默默思考。
- 不要认为一旦你给出设计方案,你的面试就结束了。直到你的面试官说你完成了,你才算完成。尽早并经常要求反馈。
每个步骤的时间分配 系统设计的面试问题通常非常广泛,45 分钟或一个小时不足以涵盖整个设计。时间管理至关重要。在每个步骤上应该花费多少时间?以下是一个非常粗略的指南,指导你在 45 分钟的面试会议中的时间分配。请记住,这只是一个粗略的估计,实际时间分配取决于问题的范围和面试官的要求。
- 第 1 步 理解问题并确定设计范围:3-10 分钟
- 第 2 步 提出高层次的设计并获得认同:10-15 分钟
- 第 3 步 深入设计:10-25 分钟
- 第 4 步 总结:3-5 分钟
第 04 章:设计一个限流器

第 05 章:一致性 hash 设计
深入讨论了一致性哈希,包括为什么需要它以及它是如何工作的。
一致性哈希的好处包括:
- 当服务器被添加或删除时,很小一部分的键被重新分配。
- 容易水平扩展,因为数据分布更加均匀。
- 缓解热点健问题。对特定分片的过度访问可能会导致服务器过载。想象一下 Katy Perry、Justin Bieber 和 Lady Gaga 的数据最终都在同一个分片上。一致性哈希通过更均匀地分配数据来缓解这个问题。
一致性哈希广泛用于现实世界的系统,包括一些著名的系统:
- 亚马逊 Dynamo 数据库的分区组件 [3]
- Apache Cassandra 中跨集群的数据分区 [4]
- Discord 聊天应用 [5]
- Akamai 内容分发网络 [6]
- Maglev 网络负载均衡器 [7]
第 06 章:key-value 存储设计
| 目标/问题 | 技术 |
|---|---|
| 存储大数据的能力 | 使用一致性哈希将负载分散到多个服务器上 |
| 高可用性读取 | 数据复制 多数据中心设置 |
| 高可用性写入 | 使用向量时钟(vector clocks)进行版本控制和冲突解决 |
| 数据分区 | 一致性哈希 |
| 增量可扩展性 | 一致性哈希 |
| 异质性(heterogeneity) | 一致性哈希 |
| 处理临时性故障 | 草率仲裁(sloppy quorum)和暗示切换(hinted handoff) |
| 处理永久性故障 | Merkle 树 |
| 处理数据中心中断 | 跨数据中心复制 |