- Published on
重新思考React最佳实践
- Authors

- Name
- AgedCoffee
- @__middle__child
重新思考 React 最佳实践
十多年前,React 重新思考了客户端渲染单页应用程序的最佳实践。
如今,React 的采用率达到了顶峰,并继续受到健康的批评和质疑。
React 18 和 React 服务器组件(RSCs)一起,标志着从最初的“视图”客户端 MVC 的标签线,到一个重要的阶段转变。
在这篇文章中,我们将试图理解 React 从 React 库到 React 架构的演变。
安娜·卡列尼娜原则指出:“所有幸福的家庭都是相似的,而每个不幸的家庭都以自己的方式不幸。”
我们将从了解 React 的核心约束和过去管理它们的方法开始。探讨团结幸福 React 应用程序的基本模式和原则。
到最后,我们将了解 React 框架(如 Remix 和 Next 13 应用程序目录)中不断变化的心智模型。
让我们从了解到目前为止一直试图解决的潜在问题开始。这将帮助我们将 React 核心团队的建议置于上下文中,即利用具有服务器、客户端和打包程序之间紧密集成的高级框架。
正在解决什么问题?
在软件工程中,通常有两类问题:技术问题和人际问题。
可以将架构看作是一种随着时间推移找到合适约束以解决这些问题的过程。
如果没有解决人际问题的正确约束,那么人们合作越多,随着时间的推移,变更的复杂性、容错性和风险性就越大。如果没有用于管理技术问题的正确约束,那么你发布的内容越多,最终用户体验通常就越差。
这些约束最终帮助我们管理作为在复杂系统中构建和互动的人类所面临的最大限制——有限的时间和注意力。
React 和人际问题
解决人际问题具有高杠杆作用。我们可以在有限的时间和关注力下提高个人、团队和组织的生产力。
团队的时间和资源有限,要快速交付。作为个人,我们的大脑容量有限,无法容纳大量的复杂性。
我们大部分时间都在弄清楚现状,以及如何最好地进行改变或添加新内容。人们需要能够在不将整个系统完全装载到头脑中的情况下进行操作。
React 的成功很大程度上归功于它与当时现有解决方案相比在管理这一约束方面的表现。它允许团队分头并行构建解耦组件,这些组件可以声明式地组合在一起,并通过单向数据流“顺利工作”。
它的组件模型和逃生舱口允许在清晰的边界内将遗留系统和集成的混乱抽象出来。然而,这种解耦和组件模型的一个影响是,很容易因为树木而忽视森林的大局。
React 和技术问题
与当时的现有解决方案相比,React 还简化了实现复杂交互功能的过程。
它的声明式模型产生了一个 n-ary 树数据结构,该结构被输入到像 react-dom 这样的特定平台的渲染器中。随着我们扩大团队并寻求现成的软件包,这个树结构很快就变得非常深入。
自 2016 年重写以来,React 积极解决了在终端用户硬件上处理大型、深度树的技术问题。
在线上,在屏幕的另一边,用户的时间和注意力也是有限的。期望值在上升,而注意力跨度在缩短。用户不关心框架、渲染架构或状态管理。他们希望无摩擦地完成需要完成的任务。另一个约束是要快速且不让用户思考。
我们将看到,下一代 React(以及 React 风格)框架中推荐的许多最佳实践都缓解了纯粹在客户端 CPU 上处理深度树所带来的影响。
回顾伟大的鸿沟
到目前为止,科技行业在不同轴线上充满了摆动,比如服务的集中化与去中心化以及薄客户端与厚客户端。
我们从厚实的桌面客户端摆动到随着 Web 的崛起变得越来越薄,再回到随着移动计算和 SPA 的崛起变得更厚的客户端。如今,React 的主导心智模型植根于这种厚实的客户端方法。
这种转变在“前端的前端”开发人员(擅长 CSS、交互设计、HTML 和可访问性模式)和“前端的后端”之间产生了分歧,因为我们在前后端分离过程中迁移到了客户端。
在 React 生态系统中,随着我们试图调和这两个世界的最佳实践,摆动的方向正在回到某个中间地带,其中很多“前端的后端”风格的代码又被移到了服务器上。
从“MVC 中的视图”到应用程序架构
在大型组织中,有一定比例的工程师作为一个平台的一部分,将架构最佳实践融入其中。
这些开发者使得其他人能够将有限的时间和精力投入到带来实际收益的事物上。
受限于有限的时间和注意力带来的一个影响是,我们通常会选择感觉最容易的方法。因此,我们希望这些积极的约束能使我们走在正确的道路上,并轻松地跌入成功的陷阱。
这个成功的重要部分在于减少需要在终端用户设备上加载和运行的代码量。遵循只下载和运行必要内容的原则。当我们局限于仅客户端的范例时,这很难遵守。包最终会包含数据获取、处理和格式化库(例如,moment.js),而这些库可以离开主线程运行。
这在像 Remix 和 Next 这样的框架中正在发生转变,React 的单向数据流扩展到了服务器,其中 MPA 的简单请求 - 响应心智模型与 SPA 的交互性相结合。
重返服务器之旅
现在让我们了解随着时间的推移,我们在这个仅客户端范例上应用了哪些优化。这需要重新引入服务器以获得更好的性能。这个背景将帮助我们理解 React 框架,其中服务器演变成为一等公民。
以下是为客户端渲染的前端提供服务的简单方法 - 带有许多 script 标签的空白 HTML 页面: 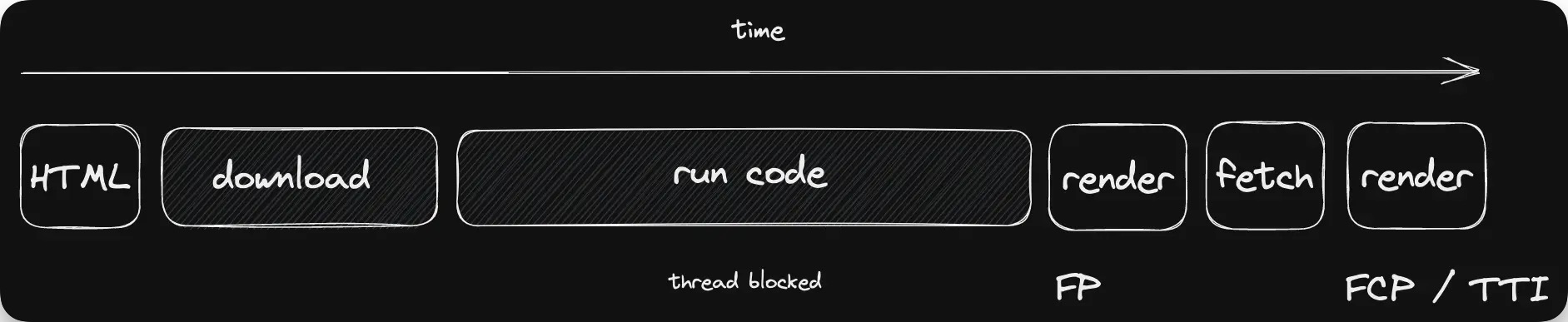 图示显示了客户端渲染的基本原理。 这种方法的优点是快速的 TTFB(首字节时间),简单的操作模型和解耦的后端。与 React 的编程模型结合,这种组合简化了许多人际问题。
图示显示了客户端渲染的基本原理。 这种方法的优点是快速的 TTFB(首字节时间),简单的操作模型和解耦的后端。与 React 的编程模型结合,这种组合简化了许多人际问题。
但是我们很快就会遇到技术问题,因为所有的责任都交给了用户硬件。我们必须等到所有内容都下载并运行,然后从客户端获取,才能显示有用的内容。
随着代码积累,只有一个地方可以存放代码。如果没有谨慎的性能管理,这可能导致应用程序运行缓慢到令人无法忍受的程度。
进入服务器端渲染
我们重返服务器的第一步是试图解决这些缓慢的启动时间。
与其用空白的 HTML 页面响应初始文档请求,我们在服务器上立即开始获取数据,然后将组件树渲染为 HTML 并响应。
在客户端渲染的 SPA 上下文中,SSR 就像是一个技巧,可以在加载 Javascript 时首先显示一些内容,而不是一片空白的白屏。  图示展示了服务器端渲染和客户端 hydration 的基本原理。 SSR 可以提高感知性能,尤其是对于内容丰富的页面。但它带来了操作成本,对于高度交互性的页面可能降低用户体验——因为 TTI(可交互时间)被进一步推迟。
图示展示了服务器端渲染和客户端 hydration 的基本原理。 SSR 可以提高感知性能,尤其是对于内容丰富的页面。但它带来了操作成本,对于高度交互性的页面可能降低用户体验——因为 TTI(可交互时间)被进一步推迟。
这被称为“不可思议的山谷”,用户在页面上看到内容并尝试与其互动,但主线程被锁定。问题仍然是过多的 Javascript。
对速度的需求 - 更多优化
因此,SSR 可以加快速度,但并非灵丹妙药。
还有一个固有的低效之处,即在服务器上渲染后,需要在客户端的 React 接管时重新执行所有操作。
较慢的 TTFB 意味着浏览器在请求文档后必须耐心等待,以便接收头部信息,从而知道需要下载哪些资源。
这就是流式传输发挥作用的地方,它为画面带来更多的并行性。
我们可以想象,如果 ChatGPT 在整个回复完成之前一直显示旋转器,大多数人会认为它已经损坏并关闭标签页。因此,我们尽早显示我们能显示的内容,通过在数据和内容完成时将其流式传输到浏览器。
对于动态页面的流式传输,是一种尽早在服务器上开始获取数据的方法,同时让浏览器开始下载资源,所有这些都是并行进行的。这比上面的图示快得多,在那里我们等待所有内容都被获取和渲染完毕,然后将带有数据的 HTML 发送给客户端。
关于流式传输的更多信息
这种流式传输技术取决于后端服务器堆栈或边缘运行时是否能够支持流式传输数据。
对于 HTTP/2,使用 HTTP 流(一种允许并发发送多个请求和响应的功能),而对于 HTTP/1,使用 Transfer-Encoding: chunked 机制,该机制允许将数据分成较小的、独立的块进行发送。
现代浏览器内置了 Fetch API,可以将获取到的响应作为可读流进行消费。
响应的 body 属性是一个可读流,允许客户端在服务器提供时逐块接收数据,而不是等待所有块一次性下载完成。
这种方法需要在服务器上设置发送流式响应的能力,并在客户端上进行读取,这需要客户端和服务器之间的密切协作。
流式传输还有一些值得注意的细微差别,例如缓存考虑因素、处理 HTTP 状态码和错误以及实际终端用户体验。在这里,快速 TTFB 与布局转换之间存在权衡。
到目前为止,我们已经优化了客户端渲染树的启动时间,通过在服务器上尽早获取数据,同时尽早刷新 HTML 以并行下载数据和资源。
现在让我们关注获取和变更数据。
数据获取约束
分层组件树的一个约束是,“一切都是组件”,这意味着节点通常具有多种职责,如发起获取操作、管理加载状态、响应事件和渲染。
这通常意味着我们需要遍历树才能知道要获取什么。
在早期,通过 SSR 生成初始 HTML 通常意味着在服务器上手动遍历树。这涉及深入到 React 内部以收集所有数据依赖关系,并在遍历树时按顺序获取。
在客户端,这种“先渲染再获取”的顺序导致加载指示器和布局变动并存。因为遍历树会导致连续的网络瀑布效果。
因此,我们需要一种方法能够并行获取数据和代码,而无需每次都从上到下遍历树才能知道要下载什么。
理解 Relay
了解 Relay 背后的原理以及它如何应对 Facebook 规模上的挑战是非常有用的。这些概念将帮助我们理解稍后将看到的模式。
组件具有并置的数据依赖
在 Relay 中,组件以 GraphQL 片段的形式声明式地定义它们的数据依赖关系。
与类似 React Query 这样也具有并置特性的库的主要区别是,组件不发起获取操作。
树遍历发生在构建时
Relay 编译器遍历树,收集每个组件的数据需求并生成一个优化的 GraphQL 查询。
通常,这个查询在运行时的路由边界(或特定的入口点)执行,允许组件代码和数据尽早并行加载。
并置支持目标的最有价值的架构原则之一 - 能够删除代码。通过删除组件,它的数据要求也被删除,查询将不再包含它们。
Relay 减轻了处理大型树形数据结构获取资源时伴随的许多权衡。
然而,它可能很复杂,需要 GraphQL,一个客户端运行时环境,以及一个高级编译器来在保持高性能的同时协调 DX 属性。
稍后我们将看到 React Server Components 如何为更广泛的生态系统遵循类似的模式。
下一个最好的选择
在获取数据和代码时,如何避免遍历树,而不采用所有这些方法呢?
这就是像 Remix 和 Next 这样的框架中服务器上的嵌套路由发挥作用的地方。
组件的初始数据依赖关系通常可以映射到 URL。其中,URL 的嵌套段映射到组件子树。这种映射使框架能够提前识别特定 URL 所需的数据和组件代码。
例如,在 Remix 中,子树可以自包含其自己的数据需求,独立于父路由,编译器确保嵌套路由并行加载。
这种封装还通过为独立子路由提供单独的错误边界来实现优雅降级。它还允许框架通过查看 URL 来提前预加载数据和代码,以实现更快的 SPA 转换。
更多的并行化
让我们深入了解 Suspense、concurrent mode 和 streaming 如何增强我们一直在探讨的数据获取模式。
Suspense 允许当数据不可用时,子树回退到显示加载界面,并在数据准备好时恢复渲染。
这是一种原语,让我们能够在本来同步的树中声明性地表示异步性。这使得我们可以在获取资源和渲染的同时实现并行。
正如我们在 streaming 中看到的,我们可以在不等待所有内容完成渲染之前就尽早地开始发送数据。
在 Remix 中,这种模式通过在路由级数据加载器中使用 defer 函数来表达:
// Remix APIs encourage fetching data at route boundaries
// where nested loaders load in parallel
export function loader ({ params }) {
// not critical, start fetching, but don't block rendering
const productReviewsPromise = fetchReview(params.id)
// critical to display page with this data - so we await
const product = await fetchProduct(params.id)
return defer({ product, productReviewsPromise })
}
export default function ProductPage() {
const { product, productReviewsPromise } = useLoaderData()
return (
<>
<ProductView product={product}>
<Suspense fallback={<LoadingSkeleton />}>
<Async resolve={productReviewsPromise}>
{reviews => <ReviewsView reviews={reviews} />}
</Async>
</Suspense>
</>
)
}
在 Next 中,RSC(React Server Components)提供了类似的数据获取模式,通过在服务器上使用异步组件来等待关键数据。
// Example of similar pattern in a server component
export default async function Product({ id }) {
// non critical - start fetching but don't block
const productReviewsPromise = fetchReview(id)
// critical - block rendering with await
const product = await fetchProduct(id)
return (
<>
<ProductView product={product}>
<Suspense fallback={<LoadingSkeleton />}>
{/* Unwrap promise inside with use() hook */}
<ReviewsView data={productReviewsPromise} />
</Suspense>
</>
)
}
这里的原则是尽早在服务器上获取数据。理想情况下,通过将加载器和 RSC 靠近数据源来实现。
为了避免不必要的等待,我们对不太关键的数据进行流式传输,使页面能够逐步分阶段加载 - 这在 Suspense 中变得很简单。
值得注意的是,RSC 本身并没有内置的 API 来支持在路由边界处获取数据。如果不小心构建,这可能会导致连续的网络瀑布式请求。
这是框架需要在内置最佳实践和提供更大灵活性以及更多表面用于误操作之间进行权衡的一条界线。
值得一提的是,当 RSC 部署在靠近数据的地方时,与客户端瀑布式请求相比,连续瀑布式请求的影响大大减小。
强调这些模式表明,RSC 需要与能够将 URL 映射到特定组件的路由器进行更高级别的框架集成。
在我们深入了解 RSC 之前,让我们花一点时间了解这幅图画的另一半。
数据变更
在仅客户端模式下管理远程数据的一种常见模式是将其存储在某种规范化存储中(例如 Redux 存储)。
在这个模型中,变更通常会乐观地更新内存中的客户端缓存,然后发送网络请求以更新服务器上的远程状态。
历史上,手动管理这些内容涉及大量的样板代码,并且容易在我们在《React 状态管理的新浪潮》中讨论的所有边缘情况中出错。
Hooks 的出现导致了像 Redux RTK 和 React Query 这样专注于处理这些边缘情况的工具的出现。
这要求通过网络传输代码以处理这些问题,其中值通过 React 上下文传播。除此之外,当遍历树时,创建低效的顺序 I/O 操作也变得容易。
那么,当 React 的单向数据流扩展到服务器时,这种现有模式将如何改变呢?
大量这种“前端背后”的样式代码实际上转移到了后端。
下面是一个摘自 Remix 中的数据流的图片,它展示了框架正在朝着 MPA(多页面应用程序)架构中的请求 - 响应模型发展的趋势。
这种转变是从将所有事物纯粹由客户端处理的模型转向服务器发挥更重要作用的模型。

你还可以查看《网络的下一次转型》以深入了解这种转变。
这种模式也扩展到了 RSC(React Server Component),我们稍后将介绍实验性的“服务器操作函数”。在这里,React 的单向数据流延伸到服务器,采用简化的请求 - 响应模型和逐步增强的表单。
从客户端删除代码是这种方法的一个好处。但是,主要的好处是简化数据管理的心智模型,这反过来又简化了许多现有的客户端代码。
理解 React 服务器组件
到目前为止,我们已经利用服务器作为优化纯客户端方法的途径。现在,我们对 React 的心智模型深深植根于用户机器上运行的客户端渲染树。
RSC(React Server Component)将服务器引入为一等公民,而不是事后优化。React 发展壮大,后端嵌入到组件树中,形成了一个强大的外层。
这种架构转变导致了许多现有关于 React 应用程序是什么以及如何部署的心智模型的变化。
最明显的两个影响是,我们迄今为止讨论过的优化数据加载模式的支持,以及自动代码拆分。
在《构建和交付大规模前端》的第二部分中,我们讨论了一些大规模关键问题,如依赖管理、国际化和优化的 A/B 测试。
当局限于纯客户端环境时,这些问题在大规模上可能难以解决。RSC 以及 React 18 的许多功能,为框架提供了一组基本工具,用于解决许多这些问题。
一个令人困惑的心智模型变化是,客户端组件可以渲染服务器组件。
这有助于帮助我们可视化一个带有 RSC 的组件树,因为它们沿着树连接在一起。客户端组件通过“孔洞”连接,提供客户端交互。
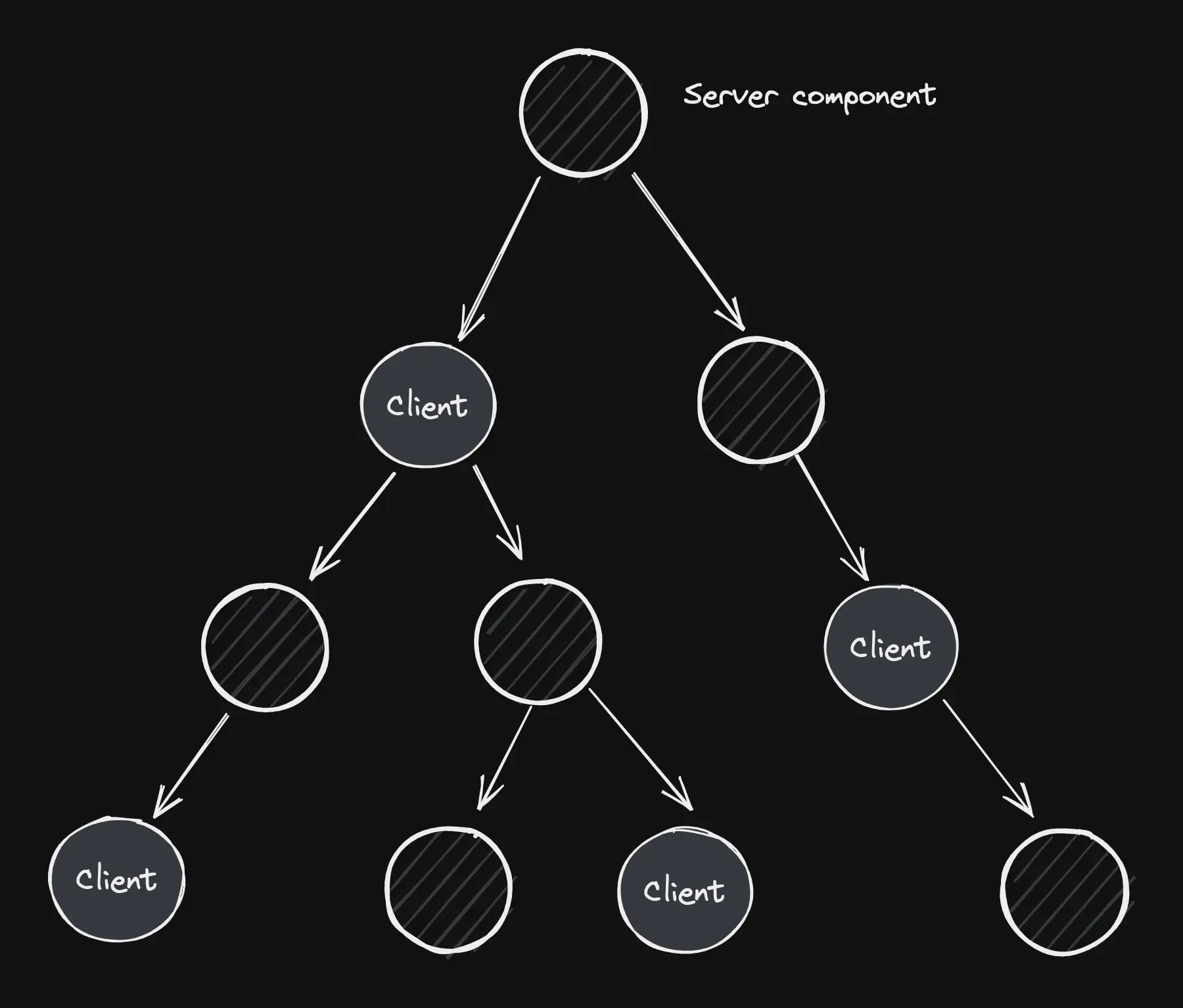
将服务器扩展到组件树下是非常强大的,因为我们可以避免向下发送不必要的代码。而且,与用户硬件不同,我们对服务器资源有更多的控制权。
树的根植根于服务器,树干穿越网络,树叶被推送到运行在用户硬件上的客户端组件上。
这种扩展模型要求我们了解组件树中的序列化边界,这些边界由 'use client' 指令标记。
这也重新强调了掌握组合的重要性,以便让 RSC 通过客户端组件中的子组件或插槽渲染到树的尽可能深的地方。
服务器操作函数
随着我们将前端的部分领域迁移到服务器,许多创新的想法正在被探讨。这些为客户端与服务器之间无缝融合的未来提供了一瞥。
如果我们可以在不需要客户端库、GraphQL 或担心运行时低效瀑布的情况下,获得与组件共同定位的好处呢?
一个服务器功能的示例可以在 React 风格的元框架 Qwik city 中看到。类似的想法也在 React (Next) 和 Remix 中探讨和讨论。
Wakuwork 仓库还为实现 React 服务器“操作函数”提供了用于数据变异的概念验证。
与任何实验性方法一样,有权衡需要考虑。在客户端 - 服务器通信方面,有关安全性、错误处理、乐观更新、重试和竞态条件的担忧。正如我们所了解到的,如果没有框架进行管理,这些问题通常无法解决。
这种探索还强调了实现最佳用户体验和最佳开发者体验往往需要提高复杂性的高级编译器优化。
结论
软件只是帮助人们完成某些事情的工具 - 许多程序员从未理解这一点。把眼睛放在交付的价值上,不要过度关注工具的细节 - 约翰·卡马克
随着 React 生态系统超越仅客户端范例的发展,了解我们下面和上面的抽象是很重要的。
清楚地理解我们操作的基本限制,使我们能够做出更明智的权衡决策。
随着每次摆动,我们获得新知识和经验来整合到下一轮迭代中。以前方法的优点仍然有效。像往常一样,这是一个权衡。
伟大之处在于框架越来越多地提供了更多杠杆工具来赋予开发人员为特定情况做出更精细化权衡。在优化用户体验与优化开发者体验相遇,并且简单模型 MPAs 与富模型 SPAs 在客户端和服务器混合中交汇。